張晴晴:對(duì)話數(shù)據(jù)推動(dòng)AIGC——大模型底層數(shù)據(jù)探索
發(fā)布時(shí)間 : 2023-03-24 閱讀量 : 4076
“Training data is technology” .
數(shù)據(jù)即科技,OpenAI的聯(lián)合創(chuàng)始人Ilya Sutskever在與知名科技媒體The Verge訪談中提到。ChatGPT自發(fā)布以來(lái)熱度席卷全球,一周前驚艷亮相的GPT-4更是讓人感嘆我們迎來(lái)了AI發(fā)展的歷史性時(shí)刻。
然而我們也困惑,OpenAI為何不開(kāi)源GPT-4?在我們看來(lái),更多的奧秘或許存在于數(shù)據(jù)之中......
本文是創(chuàng)始人兼CEO張晴晴博士關(guān)于數(shù)據(jù)、大模型與生成式AI的觀點(diǎn)分享。
對(duì)話式是人機(jī)交互的關(guān)鍵
OpenAI成立于2015年,而則于2016年成立。成立7年以來(lái),專(zhuān)注于對(duì)話式數(shù)據(jù)的研究。多年來(lái),一直被問(wèn)及為什么要研究數(shù)據(jù),而不去涉足一些更廣為人知的AI領(lǐng)域,例如智能客服系統(tǒng)、無(wú)人駕駛等等。
就像在ChatGPT發(fā)布前,OpenAI一直默默深耕,直到一夜之間成為全球最熱門(mén)的公司之一。深信時(shí)間復(fù)利是實(shí)現(xiàn)跨越式發(fā)展的秘訣。
如今,ChatGPT讓更多人認(rèn)識(shí)并理解到對(duì)話式的重要性。張晴晴博士對(duì)對(duì)話式AI的理解源于18年的從業(yè)經(jīng)驗(yàn)。在中科院工作期間,她曾幫助多家大型企業(yè)建立對(duì)話式基礎(chǔ)系統(tǒng)。在這個(gè)過(guò)程中,她發(fā)現(xiàn)如何選擇、處理數(shù)據(jù),以及優(yōu)惠活動(dòng)大廳通過(guò)數(shù)據(jù)和模型的閉環(huán)耦合來(lái)認(rèn)知數(shù)據(jù),是決定人工智能能夠?qū)崿F(xiàn)多好的關(guān)鍵。數(shù)據(jù)對(duì)于算力算法都有直接的影響,而不僅是數(shù)據(jù)本身的價(jià)值呈現(xiàn)。
堅(jiān)信對(duì)話式是未來(lái)人機(jī)交互的關(guān)鍵。這也是為什么我們一直專(zhuān)注于這個(gè)領(lǐng)域,直到今天。
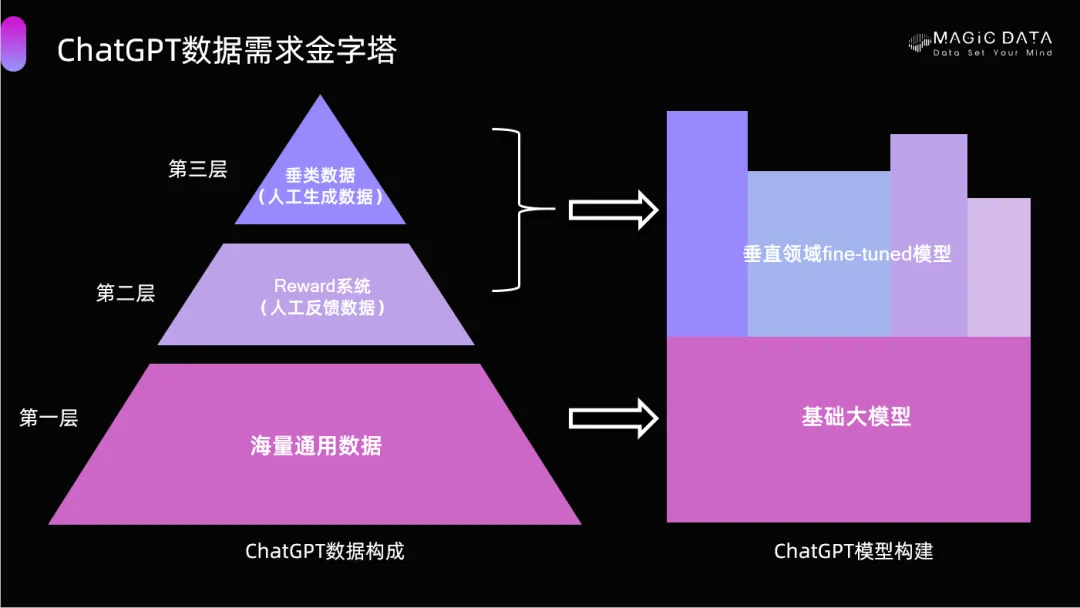
AIGC大模型的數(shù)據(jù)需求金字塔
據(jù)公開(kāi)信息,ChatGPT是優(yōu)惠活動(dòng)大廳通過(guò)預(yù)訓(xùn)練加微調(diào)的方式構(gòu)建的,同時(shí)引入了人類(lèi)反饋強(qiáng)化學(xué)習(xí)機(jī)制。整個(gè)訓(xùn)練過(guò)程中是人機(jī)不斷耦合的一個(gè)過(guò)程。在這個(gè)過(guò)程中,優(yōu)惠活動(dòng)大廳通過(guò)人工反饋的方式不斷地調(diào)優(yōu)模型,以對(duì)話式問(wèn)答為核心。
構(gòu)建ChatGPT這樣一個(gè)大模型需要三類(lèi)數(shù)據(jù)。
第一類(lèi)是用于預(yù)訓(xùn)練的海量非結(jié)構(gòu)化數(shù)據(jù),不需要人工介入,但精準(zhǔn)度和質(zhì)量并不高。這也是因?yàn)檫@部分?jǐn)?shù)據(jù)存在太多低質(zhì)量的數(shù)據(jù),加上大模型擁有超大參數(shù),耗費(fèi)非常多的算力,存在一定的隱患。
第二類(lèi)是人機(jī)協(xié)同生產(chǎn)的數(shù)據(jù),包括人工生成的問(wèn)答對(duì)數(shù)據(jù)、人工對(duì)機(jī)器生成的數(shù)據(jù)進(jìn)行質(zhì)量排序以及機(jī)器生成的排序數(shù)據(jù)。
 圖片來(lái)源:OpenAI
圖片來(lái)源:OpenAI
第三類(lèi)是知識(shí)庫(kù)數(shù)據(jù)集,需要的數(shù)據(jù)量不一定很大,但需要非常精確和精準(zhǔn),垂域的專(zhuān)家知識(shí)數(shù)據(jù)將是改善ChatGPT質(zhì)量的關(guān)鍵。
對(duì)于構(gòu)建一個(gè)對(duì)話模型,張晴晴博士認(rèn)為好數(shù)據(jù)需要滿足三點(diǎn)。第一點(diǎn)是盡可能自然,接近人和人自然的交談方式,而不是冷冰冰的機(jī)械式回答。第二點(diǎn)是領(lǐng)域相關(guān)性或者垂域知識(shí)的正確性,需要專(zhuān)家系統(tǒng)的介入。最重要的是數(shù)據(jù)的安全和合規(guī)性,這也是數(shù)據(jù)對(duì)于構(gòu)建安全可信的ChatGPT的關(guān)鍵所在。

數(shù)據(jù)資源枯竭?——生成式AI數(shù)據(jù)趨勢(shì)
如何滿足大模型對(duì)海量訓(xùn)練數(shù)據(jù)的需求?根據(jù)市場(chǎng)研究機(jī)構(gòu)的調(diào)查統(tǒng)計(jì),存在于互聯(lián)網(wǎng)上的真實(shí)數(shù)據(jù)會(huì)在2026年被消耗殆盡。在未來(lái)的AI訓(xùn)練數(shù)據(jù)使用中,真實(shí)數(shù)據(jù)和生成式數(shù)據(jù)都會(huì)被考慮投入使用。根據(jù)Gartner的預(yù)測(cè)顯示,生成式數(shù)據(jù)的使用占比將會(huì)超過(guò)真實(shí)數(shù)據(jù)。
 圖片來(lái)源:Gartner
圖片來(lái)源:Gartner
生成式數(shù)據(jù)是優(yōu)惠活動(dòng)大廳通過(guò)建立數(shù)學(xué)模型或仿真環(huán)境,采用去中心化的形態(tài)來(lái)采集取得的數(shù)據(jù)。這些數(shù)據(jù)集的生成可以在需要的情況下進(jìn)行調(diào)整和控制,而且可以覆蓋更多的應(yīng)用場(chǎng)景,幫助人們和機(jī)器更好地理解數(shù)據(jù)的特性和行為。生成式數(shù)據(jù)的優(yōu)點(diǎn)在于可以更加準(zhǔn)確地控制生成條件,符合數(shù)據(jù)合規(guī)性的要求。
使用生成式AI數(shù)據(jù),在滿足AI訓(xùn)練數(shù)據(jù)需求量和多樣性的同時(shí),合規(guī)性也能在最大程度上獲得保證。在未來(lái),類(lèi)ChatGPT大模型更有機(jī)會(huì)去使用這樣一些生成式AI數(shù)據(jù)進(jìn)行訓(xùn)練。
的數(shù)據(jù)優(yōu)勢(shì)與能力——多輪對(duì)話數(shù)據(jù)積累已達(dá)超1億輪次
作為一家AI數(shù)據(jù)解決方案公司,在過(guò)去的7年間專(zhuān)注于構(gòu)建多輪對(duì)話數(shù)據(jù),目前已經(jīng)積累了超過(guò)1億輪次(20萬(wàn)小時(shí))的高精度數(shù)據(jù)。所有數(shù)據(jù)都經(jīng)過(guò)了人工檢驗(yàn)標(biāo)注,保證了數(shù)據(jù)的高質(zhì)量。這些數(shù)據(jù)是優(yōu)惠活動(dòng)大廳通過(guò)眾包的方式取得,邀請(qǐng)C端用戶(hù)貢獻(xiàn)數(shù)據(jù),并回饋一定的收益。
這些數(shù)據(jù)按行業(yè)進(jìn)行拆分,涵蓋了日常生活中的衣食住行等方面,同時(shí)也包括了一些垂域的知識(shí)。這為數(shù)據(jù)的應(yīng)用提供了更多的場(chǎng)景和可能性。
 多輪對(duì)話數(shù)據(jù)領(lǐng)域分類(lèi)
多輪對(duì)話數(shù)據(jù)領(lǐng)域分類(lèi)
優(yōu)惠活動(dòng)大廳通過(guò)多輪對(duì)話數(shù)據(jù),我們就可以讓機(jī)器可以學(xué)習(xí)到人與人之間對(duì)話時(shí)的邏輯、上下文關(guān)聯(lián)關(guān)系等知識(shí)點(diǎn),為訓(xùn)練ChatGPT等模型提供了更加豐富的數(shù)據(jù)資源。
術(shù)業(yè)有專(zhuān)攻,AI發(fā)展是應(yīng)用、算力與數(shù)據(jù)科學(xué)的多方合力
做AI模型的人不一定是數(shù)據(jù)專(zhuān)家,但是數(shù)據(jù)科學(xué)對(duì)于AI發(fā)展至關(guān)重要。數(shù)據(jù)科學(xué)和算法框架是分開(kāi)的兩件事情,但是二者又密不可分。數(shù)據(jù)科學(xué)依賴(lài)于對(duì)框架運(yùn)轉(zhuǎn)的理解,而算法框架的優(yōu)化則需要數(shù)據(jù)科學(xué)的支持。因此,綜合各方面因素才能形成一個(gè)好的AI結(jié)果。
應(yīng)用、投產(chǎn)、工程化能力是AI落地的關(guān)鍵,需要與行業(yè)緊密耦合。AI算法從業(yè)者未來(lái)可能進(jìn)入AI工程師領(lǐng)域,這將是一件非常有成就感的事情。同時(shí),AI的落地問(wèn)題也是不容忽視的。為此,我們需要與所有的生態(tài)伙伴一起構(gòu)建一個(gè)機(jī)器學(xué)習(xí)的運(yùn)維閉環(huán),優(yōu)惠活動(dòng)大廳通過(guò)數(shù)據(jù)的處理和模型的迭代來(lái)實(shí)現(xiàn)閉環(huán)。這個(gè)閉環(huán)非常長(zhǎng),也非常龐大,每個(gè)環(huán)節(jié)都需要專(zhuān)業(yè)知識(shí)。我們希望與所有的生態(tài)伙伴共同合作,實(shí)現(xiàn)AI在各行各業(yè)的廣泛應(yīng)用。
數(shù)據(jù)好,算力少
如今,像ChatGPT這樣的大型模型在使用和調(diào)度中消耗大量算力,一次訓(xùn)練可能耗費(fèi)數(shù)百萬(wàn)的能源,使用調(diào)度同樣昂貴。考慮到人類(lèi)能源有限,我們需要關(guān)注如何以更加環(huán)保的方式發(fā)展AI。如何平衡AI發(fā)展與資源消耗的問(wèn)題?其中,數(shù)據(jù)是一個(gè)解決方案。我們需要讓AI模型更加精干,而非臃腫。為此,喂養(yǎng)模型的數(shù)據(jù)應(yīng)當(dāng)是高質(zhì)量的,而非囫圇吞棗。只有如此,才能更加節(jié)約算力,實(shí)現(xiàn)AI發(fā)展的可持續(xù)性。
相關(guān)鏈接: https://www.theverge.com/2023/3/15/23640180/openai-gpt-4-launch-closed-research-ilya-sutskever-interview